
El algoritmo desarrollado por una científica argentina que “aprendió” a detectar plantas en peligro de extinción

¿Cómo es posible entrenar una computadora para que realice una de las tareas más difíciles en materia de conservación?
Eso es precisamente lo que hizo la científica argentina Anahí Espíndola, profesora de entomología de la Universidad de Maryland en Estados Unidos.
Espíndola es una de las creadoras de una nueva herramienta nada convencional que busca proteger plantas en peligro de extinción.
La investigadora y sus colegas crearon un algoritmo que "aprende" a identificar las especies con más probabilidad de estar en riesgo de desaparición.
Lista Roja
Una de las guías más importantes de especies amenazadas es la llamada Lista Roja que elabora la Unión Internacional para la Conservación de la Naturaleza (IUCN, por sus siglas en inglés).
La lista evalúa cada especie de forma individual en función de características como la reducción de poblaciones o el tamaño del área de distribución.

Y luego clasifica esas especies en distintas categorías en función de su necesidad de conservación.
Las categorías van desde "preocupación menor" hasta "en peligro crítico".
"El problema es que para hacer estas clasificaciones se evalúa una especie después de otra. Se evalúan por ejemplo todas las especies en una familia, pero algunas de las especies en esa familia no están en peligro", explicó a BBC Mundo Espíndola.
Se trata de un proceso complejo, que requiere mucho tiempo y para el que "se necesitan muchos fondos y conocimiento técnico".
Algoritmo que aprende
De hecho, se estima que solamente el 5% de todas las especies conocidas de plantas han sido evaluadas para la Lista Roja.
"Pensando en este problema se nos ocurrió usar un algoritmo no para reemplazar la evaluaciones de la Lista Roja, sino para hacer el proceso más dirigido hacia las especies con mayor probabilidad de peligro de extinción", señaló la científica argentina.
Pero ¿cómo lograron los investigadores "entrenar" un algoritmo para que identifique plantas amenazadas?

Los científicos crearon el algoritmo a partir de los datos que ya tenían sobre plantas amenazadas y sus características, como por ejemplo la distribución en función de la longitud y latitud, clima o morfología.
"Creamos un modelo para esas especies que uno ya conoce, y la idea es ver si esas características morfológicas, espaciales o climáticas, pueden ayudarnos a separar las especies que tienen riesgo de conservación de las que no lo tienen", afirmó Espíndola.
"Una vez que creamos este modelo con los datos que ya conocemos, podemos usarlo para predecir especies que no han sido evaluadas pero para las que sí tenemos características climáticas o de morfología".
Sorpresas
El algoritmo entrenado, un ejemplo de lo que se denomina machine learning o aprendizaje automatizado, arrojó varias sorpresas.
En total, el algoritmo fue alimentado con datos de 150.000 especies de plantas. De ellas, más de 15.000 (un 10%) resultaron tener una alta probabilidad de ser clasificadas con algún tipo de riesgo en la Lista Roja.
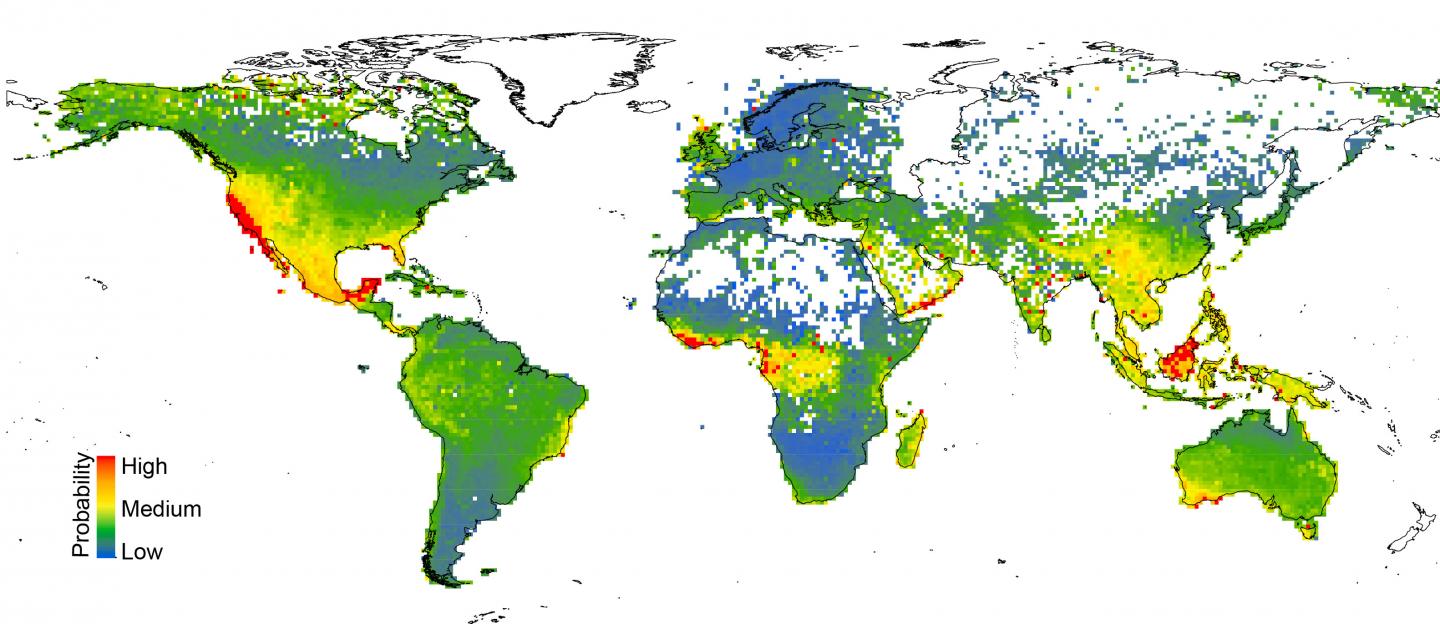
Los mapas generados por el estudio destacaron la necesidad de conservar algunas áreas ya conocidas por su biodiversidad.
"Pero muchas veces había regiones que no estaban estudiadas, como el sur de la Península Arábiga, que aparecen con alta probabilidad de necesidad de conservación y no son regiones conocidas como centros de biodiversidad global", explicó Espíndola a BBC Mundo.
"En América Latina, las regiones con probabilidad más alta que identificamos son los Andes, en Ecuador y Perú; y los bosques de la costa sureste de Brasil, el bosque atlántico".
Espíndola señaló que el modelo "puede ser adaptado para cualquier escala".
"Todo lo que hicimos es de acceso abierto y los datos que usamos están disponibles públicamente", señaló la investigadora.
"Esperamos ahora que la gente use nuestro modelo y nos indique si encuentra algún problema, para poder mejorarlo", concluyó.
Ahora puedes recibir notificaciones de BBC News Mundo. Descarga la nueva versión de nuestra app y actívalas para no perderte nuestro mejor contenido.
